Home > Tech Gallery > How CXL Technology Solves Memory Problems in Data Centres (Part 1)

Time: December 10th, 2024




Compute Express Link (CXL) represents a novel device interconnection technology standard that has emerged as a significant advancement in the storage sector, particularly in addressing memory bottlenecks. CXL serves not only to expand memory capacity and bandwidth but also facilitates heterogeneous interconnections and the decoupling of resource pools within data centres. By enabling the interconnection of various computing and storage resources, CXL technology effectively mitigates memory-related challenges in data centres, resulting in enhanced system performance and efficiency.
CXL The Emergence of Technology
The rapid advancement of applications such as cloud computing, big data analytics, artificial intelligence, and machine learning has resulted in a significant increase in demand for data storage and processing within data centres. Traditional DDR memory interfaces present challenges related to overall bandwidth, average bandwidth per core, and limitations concerning capacity scalability. This is particularly critical in data centre environments, which face numerous memory-related constraints. Consequently, innovative memory interface technologies, such as CXL, have emerged to address these issues.
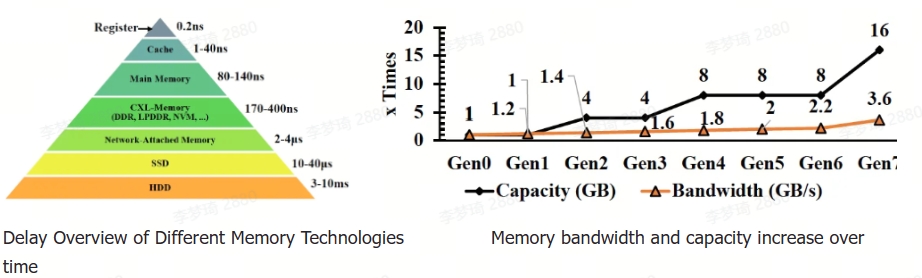
In data centres, the relationship between CPU and memory remains tightly coupled, with each generation of CPUs adopting new memory technologies to attain higher capacity and bandwidth. Since 2012, there has been a rapid increase in the number of CPU cores; however, the memory bandwidth and capacity allocated to each core have not experienced a corresponding increase and have decreased. This trend is expected to persist in the future, with memory capacity advancing at a faster rate than memory bandwidth, which could significantly impact overall system performance.
Furthermore, there exists a substantial delay and cost gap between DRAM and SSD, which often leads to the underutilization of expensive memory resources. Incorrect calculations and memory ratios can easily result in memory idleness, manifesting as stranded memory resources that cannot be effectively utilized. The data centre sector, recognized as one of the most capital-intensive industries worldwide, exhibits low utilization rates, posing a considerable financial burden. According to Microsoft, 50% of the total costs associated with servers are attributable to DRAM. Despite the high expense of DRAM, it is estimated that approximately 25% of DRAM memory remains unutilized. Internal statistics from Meta reflect similar trends. Notably, the proportion of memory costs relative to total system costs is rising, shifting the primary cost burden from the CPU to memory resources. Employing CXL technology to create a memory resource pool may provide an effective solution by dynamically allocating memory resources and optimizing the computation-to-memory total cost of ownership (TCO) ratio.
In data centres, the relationship between CPU and memory remains tightly coupled, with each generation of CPUs adopting new memory technologies to attain higher capacity and bandwidth. Since 2012, there has been a rapid increase in the number of CPU cores; however, the memory bandwidth and capacity allocated to each core have not experienced a corresponding increase and have decreased. This trend is expected to persist in the future, with memory capacity advancing at a faster rate than memory bandwidth, which could significantly impact overall system performance.
Furthermore, there exists a substantial delay and cost gap between DRAM and SSD, which often leads to the underutilization of expensive memory resources. Incorrect calculations and memory ratios can easily result in memory idleness, manifesting as stranded memory resources that cannot be effectively utilized. The data centre sector, recognized as one of the most capital-intensive industries worldwide, exhibits low utilization rates, posing a considerable financial burden. According to Microsoft, 50% of the total costs associated with servers are attributable to DRAM. Despite the high expense of DRAM, it is estimated that approximately 25% of DRAM memory remains unutilized. Internal statistics from Meta reflect similar trends. Notably, the proportion of memory costs relative to total system costs is rising, shifting the primary cost burden from the CPU to memory resources. Employing CXL technology to create a memory resource pool may provide an effective solution by dynamically allocating memory resources and optimizing the computation-to-memory total cost of ownership (TCO) ratio.
The proportion of rack TCO/power consumption across different generations
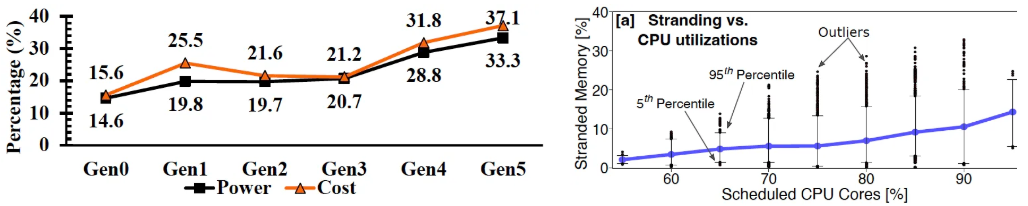
Microsoft Azure memory idle
The industry has been actively pursuing the adoption of new memory interface technologies and system architectures in response to traditional memory limitations.
Among various memory interface technologies, PCI-Express (Peripheral Component Interconnect Express) has emerged as the predominant choice. As a serial bus, PCIe presents certain challenges, including relatively high communication overhead between different devices from both performance and software perspectives. However, there is encouraging news: the PCIe 7.0 specification was completed at the end of 2023, promising data transfer speeds of up to 256 GB/s. While the current PCIe 4.0 edition, with a data rate of 16 GT/s, is not yet universally adopted, the advancement is expected to progress in the coming years. The primary impetus driving the development of PCIe is the escalating demand for cloud computing solutions. Historically, PCIe has seen its data transmission rates double every three to four years, demonstrating a consistent trajectory of innovation and enhancement within the field.
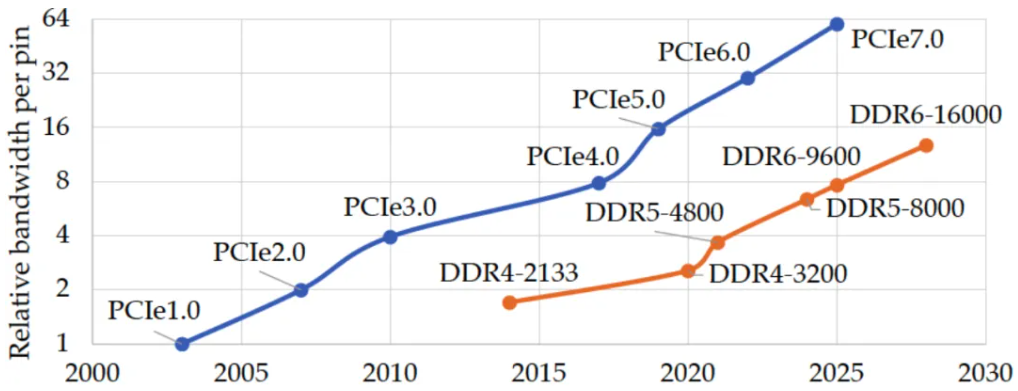
PCIe vs DDR Bandwidth comparison
The system architecture has experienced multiple generations of evolution. Initially, the focus was on facilitating the sharing of a resource pool among multiple servers, typically employing RDMA (Remote Direct Memory Access) technology over standard Ethernet or InfiniBand networks. This initial implementation often led to higher communication delays, with local memory access times being several tens of nanoseconds compared to RDMA, which typically resulted in delays of a few microseconds. Additionally, this method demonstrated lower bandwidth and failed to provide essential features such as memory consistency.
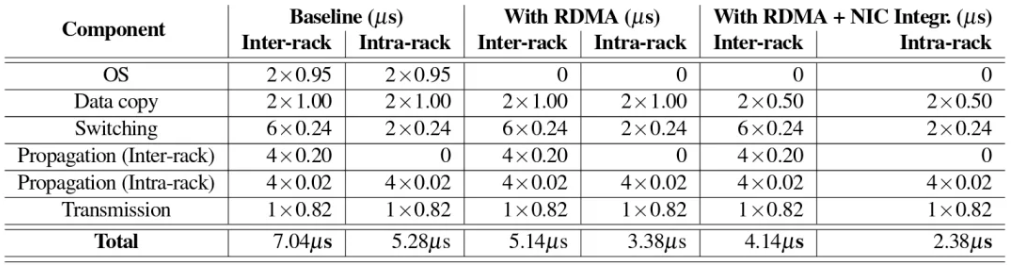
In networks utilizing 40 Gbps link bandwidth, the total achievable round-trip delay is influenced by various components that contribute to increased latencies.
The adoption of 100 Gbps technology can effectively reduce data transmission delays by approximately 0.5 microseconds.
In 2010, CCIX emerged as a potential industry standard, driven by the necessity for faster interconnections exceeding the capabilities of existing technologies, as well as the requirement for cache coherence to facilitate expedited access to memory in heterogeneous multiprocessor systems. Despite its reliance on PCI Express standards, CCIX has not gained significant traction, primarily due to insufficient support from pivotal industry stakeholders.
Conversely, CXL builds on the established PCIe 5.0 physical and electrical layer standards and ecosystem, incorporating features of cache consistency and low latency for memory load/store transactions. The establishment of industry-standard protocols endorsed by numerous major players has rendered CXL pivotal for advancing heterogeneous computing, resulting in robust industry support. Notably, AMD's Genoa and Intel's Sapphire Rapids processors have supported CXL 1.1 since late 2022 or early 2023. Consequently, CXL has emerged as one of the most promising technologies within both the industry and academia for addressing this critical issue.
CXL operates on the PCIe physical layer, leveraging existing PCIe physical and electrical interface features to deliver high bandwidth and scalability. Moreover, CXL presents lower latency compared to conventional PCIe interconnects, alongside a unique array of features that enable central processing units (CPUs) to interact with peripheral devices—such as memory expanders and accelerators and their associated storage—within a cache-coherent framework, utilizing load/store semantics. This innovation ensures consistency between CPU memory space and additional device memory, thereby facilitating resource sharing that enhances performance while streamlining software stack complexity. Memory-related device expansion represents one of the primary target scenarios for CXL implementation.
Flex Bus x16 Connector/Slot

CXL relies on the existing PCIe Physical and electrical interface characteristics
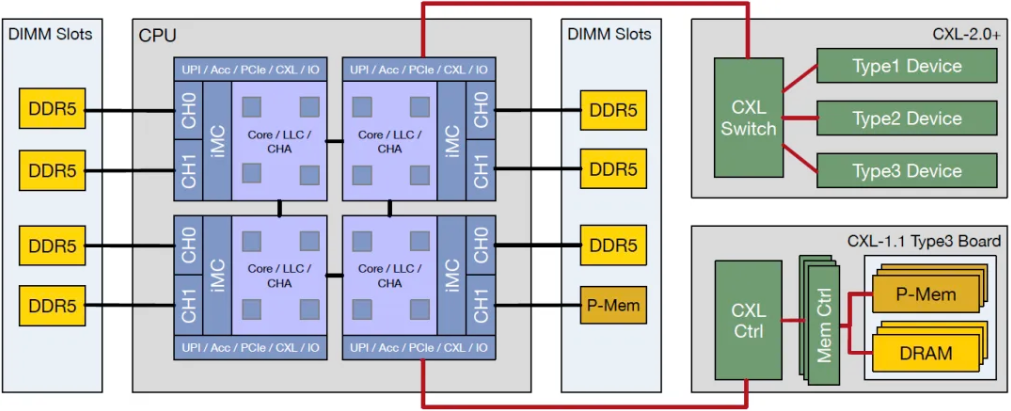
CXL/PCIe implementation for memory resource expansion/pool
CXL The Principle of Technology
CXL encompasses three protocols; however, it is important to note that not all protocols effectively address latency issues. CXL.io, which operates on the physical layer of the PCIe bus, exhibits latency characteristics comparable to those of previous technologies. In contrast, the other two protocols, CXL.cache and CXL.mem, utilize optimized pathways that significantly reduce latency. Most CXL memory controllers are expected to introduce an increase in latency of approximately 100 to 200 nanoseconds, with additional re-timers potentially contributing an incremental delay measured in tens of nanoseconds, contingent upon the distance separating the device from the CPU.
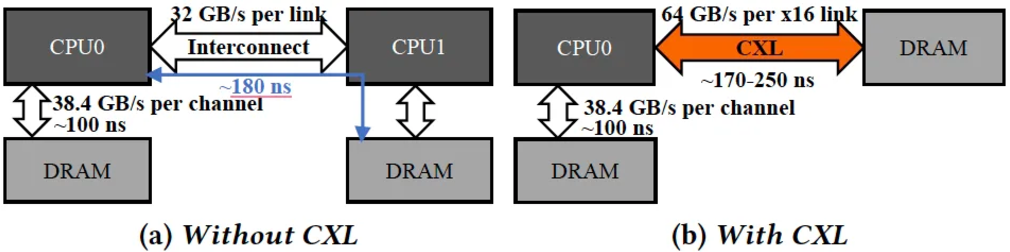
CXL introduces latency similar to NUMA
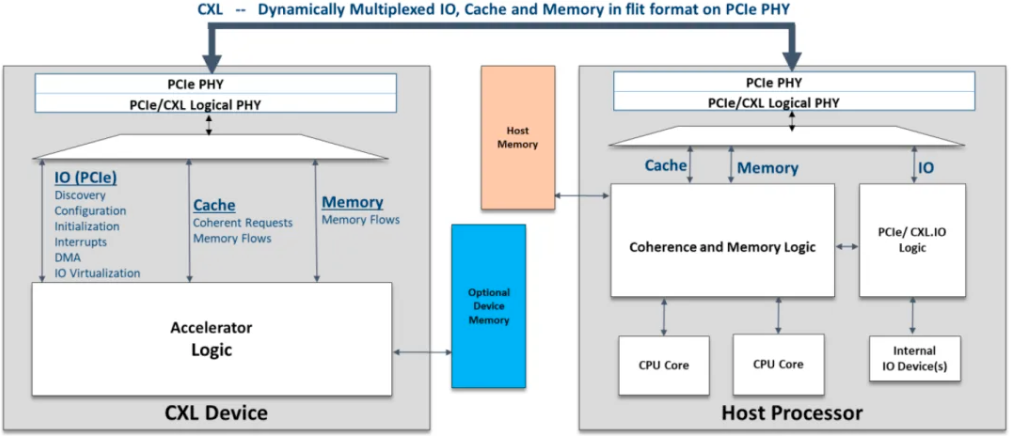
CXL/PCIe Expand Memory System Framework Construction
The CXL (Compute Express Link) standard incorporates various protocols at the PCIe PHY layer, with the CXL 1.0 and 1.1 specifications encompassing three distinct protocols: CXL.io, CXL.cache, and CXL.mem. A majority of CXL devices are designed to utilize a combination of these protocols. Notably, CXL.io employs the same Transaction Layer Packet (TLP) and Data Link Layer Packet (DLLP) as PCIe, where the TLP/DLLP is integral to the payload component of the CXL flit.
CXL establishes protocols to ensure the requisite quality of service (QoS) across diverse protocol stacks. The reuse of PHY-level protocols guarantees that delay-sensitive protocols, such as CXL.cache and CXL.mem, maintain latency levels comparable to those of native CPU-to-CPU symmetric consistency links. Furthermore, CXL has implemented upper limits on pin-to-pin response times for these latency-sensitive protocols, thereby ensuring that overall platform performance remains unaffected by considerable latency disparities among the various devices that implement consistency and memory semantics.
●
CXL.io can be regarded as a standard for PCIe, representing an enhanced version of the technology.
● It functions as a protocol for initialization, linking, device discovery, enumeration, and access registration. Additionally, it offers interfaces for input/output devices, akin to PCIe Gen5. It is essential for CXL devices to also support CXL.io.
● CXL.cache delineates a relationship between the host, typically a CPU, and devices such as memory modules or accelerators, facilitating their interaction via the CXL protocol.
● CXL.cache delineates a relationship between the host, typically a CPU, and devices such as memory modules or accelerators, facilitating their interaction via the CXL protocol.
● Through the secure usage of its local copy, CXL.cache enables seamless access and caching of the host's memory by CXL devices. This can be likened to a GPU directly retrieving data from the CPU's memory cache.
● CXL.mem serves as a protocol that grants host processors, usually CPUs, direct memory access attached to devices through load/store commands.
● CXL.mem serves as a protocol that grants host processors, usually CPUs, direct memory access attached to devices through load/store commands.
● This allows for coherent access by the host CPU to the device's memory, paralleling the use of dedicated storage-class memory devices or memory on accelerator devices, such as GPUs.
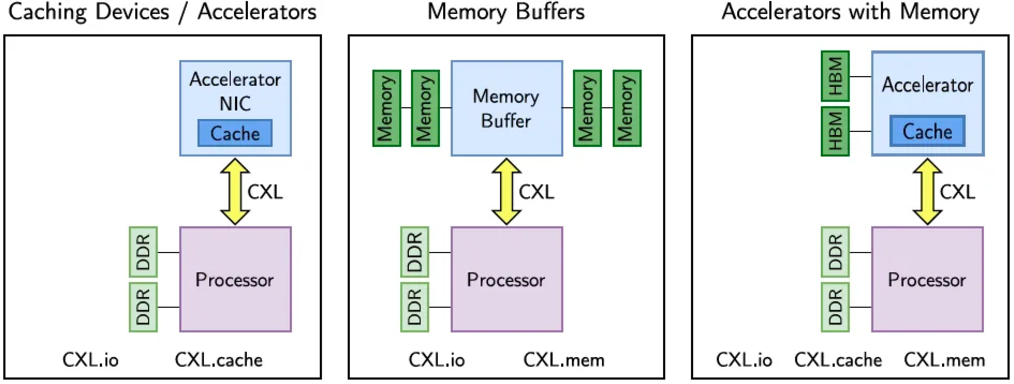
From left to right, in order, are CXLType1, CXLType3, and CXLType2
CXL 2.0 has enhanced the memory pool capabilities and the support for exchange among numerous hosts and devices, facilitating seamless connectivity and communication within the CXL framework. This advancement has significantly increased the number of devices that can be interconnected in a network environment. Multiple hosts can establish connections to a switch, which in turn connects to various devices. In instances where a CXL device possesses multiple heads and is linked to the root ports of multiple hosts, implementation without a switch remains feasible.
The architecture features two key configurations: Single Logical Device (SLD) and Multiple Logical Devices (MLD). The SLD configuration allows a single host to utilize different memory pools independently, while the MLD configuration is designed to enable multiple hosts to share a common physical memory pool.
Management of this distributed memory resource network will be executed by the Structure Manager, also known as the Fabric Manager. This manager is responsible for memory allocation and device orchestration, functioning as a control plane or coordinator located on a separate chip or within a switch. The Structure Manager typically does not require high performance, as it does not engage directly with the data plane. It provides standards for controlling and managing the system, thereby enabling fine-grained resource allocation. Features such as hot swapping and dynamic scaling facilitate the dynamic allocation and transfer of hardware between hosts without necessitating a system reboot.
In conclusion, a report from Microsoft indicates that the adoption of CXL methodologies can lead to a reduction of approximately 10% in memory resource pool demand, thus potentially lowering total server costs by about 5%.
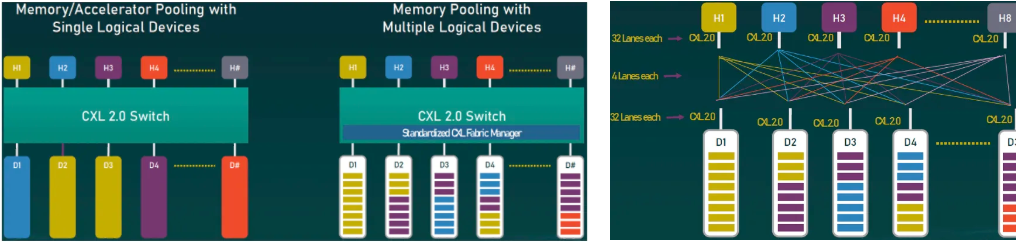
CXL 2.0 Memory Resource Pool (Switch vs Direct Connect Mode)
CXL The Development of Technology
CXL is experiencing significant momentum in its development, with major corporations such as Samsung, SK Hynix, Marvell, Rambus, and AMD accelerating their engagement in this technology. Large enterprises, including public cloud providers, are beginning to explore the integration of CXL to connect memory pools, thereby enhancing memory utilization and addressing the dynamic demands for increased bandwidth and capacity. However, there is currently a limited availability of applications for local use, particularly regarding the multi-level memory scheduling management and monitoring technologies associated with external mixed resource pools. Consequently, should cloud service providers choose to implement a large-scale resource pool system based on CXL technology, they will need to either develop the necessary infrastructure internally or identify suitable hardware and software suppliers. In this regard, leading cloud service providers such as Microsoft and Meta have taken initiatives ahead of others.
Microsoft's Pond initiative employs machine learning to evaluate whether a virtual machine is latency-sensitive and underutilized. By assessing the size of untouched memory, the initiative determines the most appropriate scheduling for virtual machines in either local or CXL remote memory locations, continuously adjusting for migration in alignment with the performance monitoring system.
Microsoft's Pond initiative employs machine learning to evaluate whether a virtual machine is latency-sensitive and underutilized. By assessing the size of untouched memory, the initiative determines the most appropriate scheduling for virtual machines in either local or CXL remote memory locations, continuously adjusting for migration in alignment with the performance monitoring system.
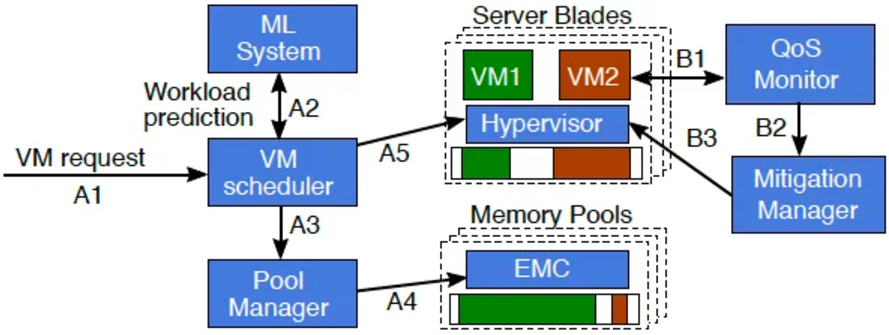
Microsoft Pond Scheme Control Plane Workflow Program
1. The virtual machine (VM) scheduler employs machine learning-based predictions to identify latency-sensitive virtual machines and to determine their optimal placement based on the memory that may remain unused.
2. In instances where service quality (QoS) standards are not met, the scheduling migration control manager, referred to as the Mitigation Manager, will initiate the reconfiguration of the virtual machine.
As a leader in the construction of intelligent computing centre networks, Ruijie Networks is dedicated to delivering innovative product solutions and services to clients, fostering industry advancement and innovation, and facilitating a closer connection between clients and the future. Ruijie Networks will persist in its commitment to innovation and will guide the evolution of network development in the era of intelligent computing.
-20241210-111245.png)
Related Blogs:
Exploration of Data Center Automated Operation and Maintenance Technology: Zero Configuration of Switches
Technology Feast | How to De-Stack Data Center Network Architecture
Technology Feast | A Brief Discussion on 100G Optical Modules in Data Centers
Research on the Application of Equal Cost Multi-Path (ECMP) Technology in Data Center Networks
Technology Feast | How to build a lossless network for RDMA
Technology Feast | Distributed VXLAN Implementation Solution Based on EVPN
Exploration of Data Center Automated Operation and Maintenance Technology: NETCONF
Technical Feast | A Brief Analysis of MMU Waterline Settings in RDMA Network
Technology Feast | Internet Data Center Network 25G Network Architecture Design
Technology Feast | The "Giant Sword" of Data Center Network Operation and Maintenance
Technology Feast: Routing Protocol Selection for Large Data Centre Networks
Technology Feast | BGP Routing Protocol Planning for Large Data Centres
Technology Feast | Talk about the next generation 25G/100G data centre network
Technology Feast | Ruijie Data Center Switch ACL Service TCAM Resource Evaluation Guide
Silicon Photonics Illuminates the Path to Sustainable Development for Data Centre Networks
As a leader in the construction of intelligent computing centre networks, Ruijie Networks is dedicated to delivering innovative product solutions and services to clients, fostering industry advancement and innovation, and facilitating a closer connection between clients and the future. Ruijie Networks will persist in its commitment to innovation and will guide the evolution of network development in the era of intelligent computing.
Related Blogs:
Exploration of Data Center Automated Operation and Maintenance Technology: Zero Configuration of Switches
Technology Feast | How to De-Stack Data Center Network Architecture
Technology Feast | A Brief Discussion on 100G Optical Modules in Data Centers
Research on the Application of Equal Cost Multi-Path (ECMP) Technology in Data Center Networks
Technology Feast | How to build a lossless network for RDMA
Technology Feast | Distributed VXLAN Implementation Solution Based on EVPN
Exploration of Data Center Automated Operation and Maintenance Technology: NETCONF
Technical Feast | A Brief Analysis of MMU Waterline Settings in RDMA Network
Technology Feast | Internet Data Center Network 25G Network Architecture Design
Technology Feast | The "Giant Sword" of Data Center Network Operation and Maintenance
Technology Feast: Routing Protocol Selection for Large Data Centre Networks
Technology Feast | BGP Routing Protocol Planning for Large Data Centres
Technology Feast | Talk about the next generation 25G/100G data centre network
Technology Feast | Ruijie Data Center Switch ACL Service TCAM Resource Evaluation Guide
Silicon Photonics Illuminates the Path to Sustainable Development for Data Centre Networks
Featured blogs






